PDF Extractor API (aka PDFex) is a developer-first service designed to turn PDFs into clean, structured JSON data. It reliably extracts information from invoices, receipts, forms, statements, and other business documents, allowing your applications to consume the data immediately. Built for performance, predictable results, and rapid integration, PDFex eliminates the need for manual parsing and brittle OCR glue, enabling teams to automate data ingestion with confidence.
This API is ideal for developers looking to integrate PDF data extraction capabilities into their backend systems. Whether you're working on an invoice processing system, a document management platform, or any application that requires structured data from PDFs, PDF Extractor API provides a powerful and flexible solution. Its intuitive workflow allows users to create, map, and deploy PDF templates quickly, making it easy to start extracting meaningful data from PDFs in a structured format.
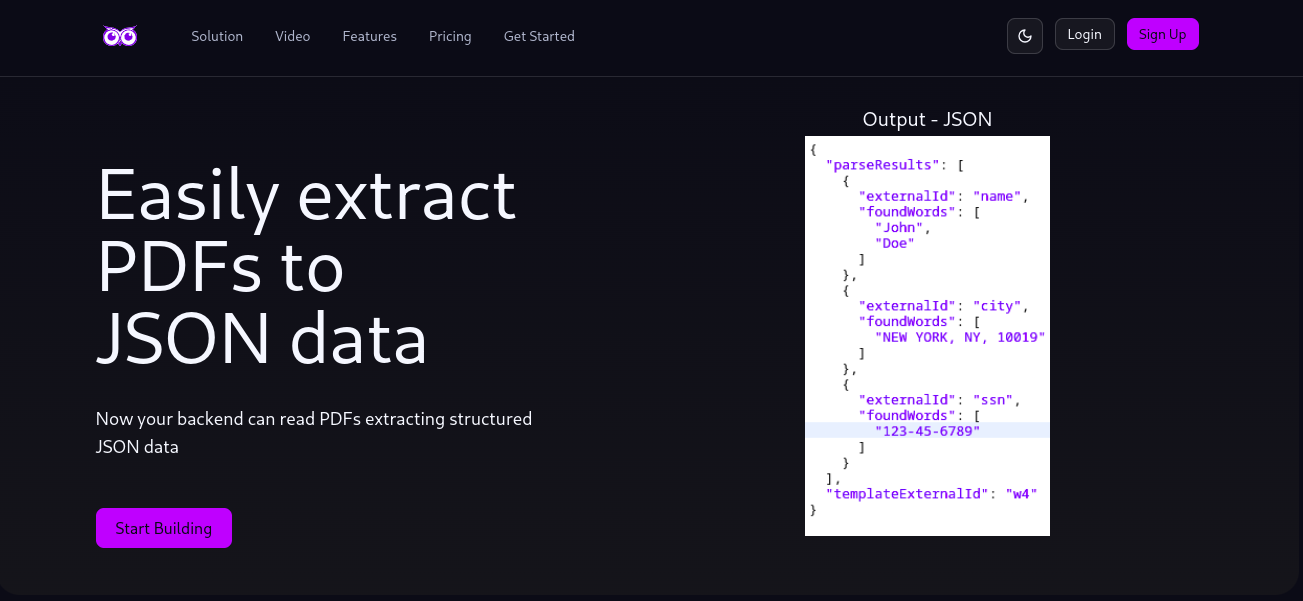
The core functionality of PDF Extractor API involves taking a PDF file as input and converting it into a structured JSON output. This process includes identifying key fields such as invoice amounts, client names, and user identification numbers. The API uses intelligent mapping to extract the desired data, ensuring accuracy and consistency across different document formats.
Developers can integrate the API into their backend systems using straightforward API calls. Once integrated, they can upload PDFs and receive structured JSON data that can be used directly in their applications. The API also supports customization, allowing users to define which fields they want to extract based on their specific requirements.
PDF Extractor API offers several benefits that make it a valuable tool for developers and businesses alike:
| Benefit | Description |
|---|---|
| Efficiency | Automates the process of data extraction from PDFs, saving time and reducing errors |
| Scalability | Offers different pricing tiers to accommodate various usage levels |
| Accuracy | Uses advanced algorithms to ensure reliable and consistent data extraction |
| Flexibility | Allows users to define and extract custom fields based on their needs |
| Integration | Easy to integrate with existing backend systems through a well-documented API |
By leveraging PDF Extractor API, teams can streamline their data processing workflows and focus on building better applications.