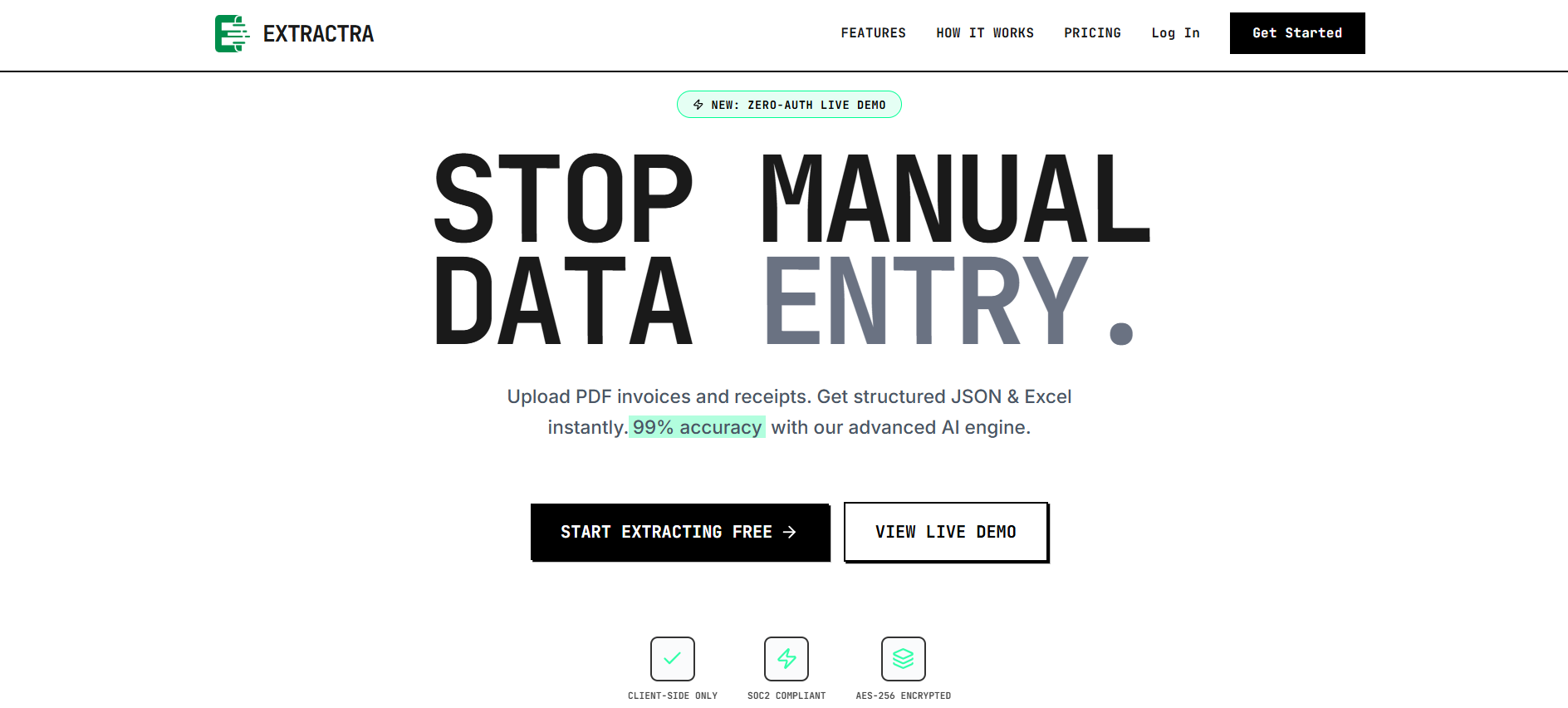
Extractraは、請求書、領収書、発注書、送り状、税務書類などの非構造化文書から構造化データを自動抽出するAI駆動型ドキュメント処理ソリューションです。PDF形式のスキャン画像またはデジタル文書をExcel、CSV、JSONといった構造化フォーマットへ変換し、手作業によるデータ入力を不要にします。主に財務部門、会計チーム、調達担当者、およびドキュメント処理を自動化したいソフトウェア開発者が対象です。
従来のOCRツールとは異なり、Extractraはルールベースの設定やテンプレート作成を必要としません。多様な文書レイアウトに学習済みのAIエンジンが、ユーザーによる事前設定なしでキーバリューペアや表形式のデータを正確に識別・抽出します。アップロードおよび初期処理は完全にクライアントサイドで実行されるため、機密性の高い財務データはユーザーのブラウザを離れることがありません(API経由での明示的な転送を除く)。
Extractraは「アップロード」「抽出」「エクスポート」の3ステップで動作します。ユーザーはまずPDFファイル(複数ページ対応)をドラッグ&ドロップでインターフェースにアップロードします。システムはこれらのファイルを並列で処理し、文書のレイアウトを解析し、発行者名、請求日付、明細項目といった意味的領域を認識してキーバリューペアおよび表形式データを抽出します。手動設定やテンプレート学習は一切不要です。
抽出プロセスでは、検証ロジックが適用され、標準的な請求書および領収書フォーマットにおいて99%以上の精度が保証されます。処理完了後、ユーザーはExcel、CSV、JSON形式で結果をダウンロードするか、REST APIを用いてプログラムによる連携を行います。企業向けには認証、レート制限、ペイロードカスタマイズに対応したAPI機能が提供されます。
Extractraは、仕入先支払処理(AP)、経費精算、財務報告などの業務における運用負荷を低減します。財務チームは請求書処理期間の短縮、データ入力ミスの削減、月次決算の迅速化に活用しています。調達部門は発注書や納品書からサプライヤー情報を標準化して取り込むためにバッチ抽出を活用します。開発者はERP、会計ソフトウェア、または独自ワークフローにAPIを統合し、システム間の手動データ再入力を排除しています。
プラットフォームは小規模事業者から大企業まで、処理量に応じたスケーラビリティを備えており、各プランは月間ページ数上限、1文書あたり最大ページ数、処理優先度、サポート体制を段階的に拡張します。クライアントサイド実行、エンドツーエンド暗号化、SOC2 Type II認証といったセキュリティ要件を満たすため、金融情報を取り扱う規制産業でも安全に導入可能です。
| プラン | 月間ページ数 | 1文書あたり最大ページ数 | 処理優先度 | サポート体制 |
|---|---|---|---|---|
| 無料版 | 5 | 5 | 基本 | コミュニティ |
| Pro | 1,500 | 50 | 標準 | メール |
| Pro Plus | 5,000 | 100 | 優先 | 優先 |
| Business | 10,000 | 150 | 即時 | 専任 |