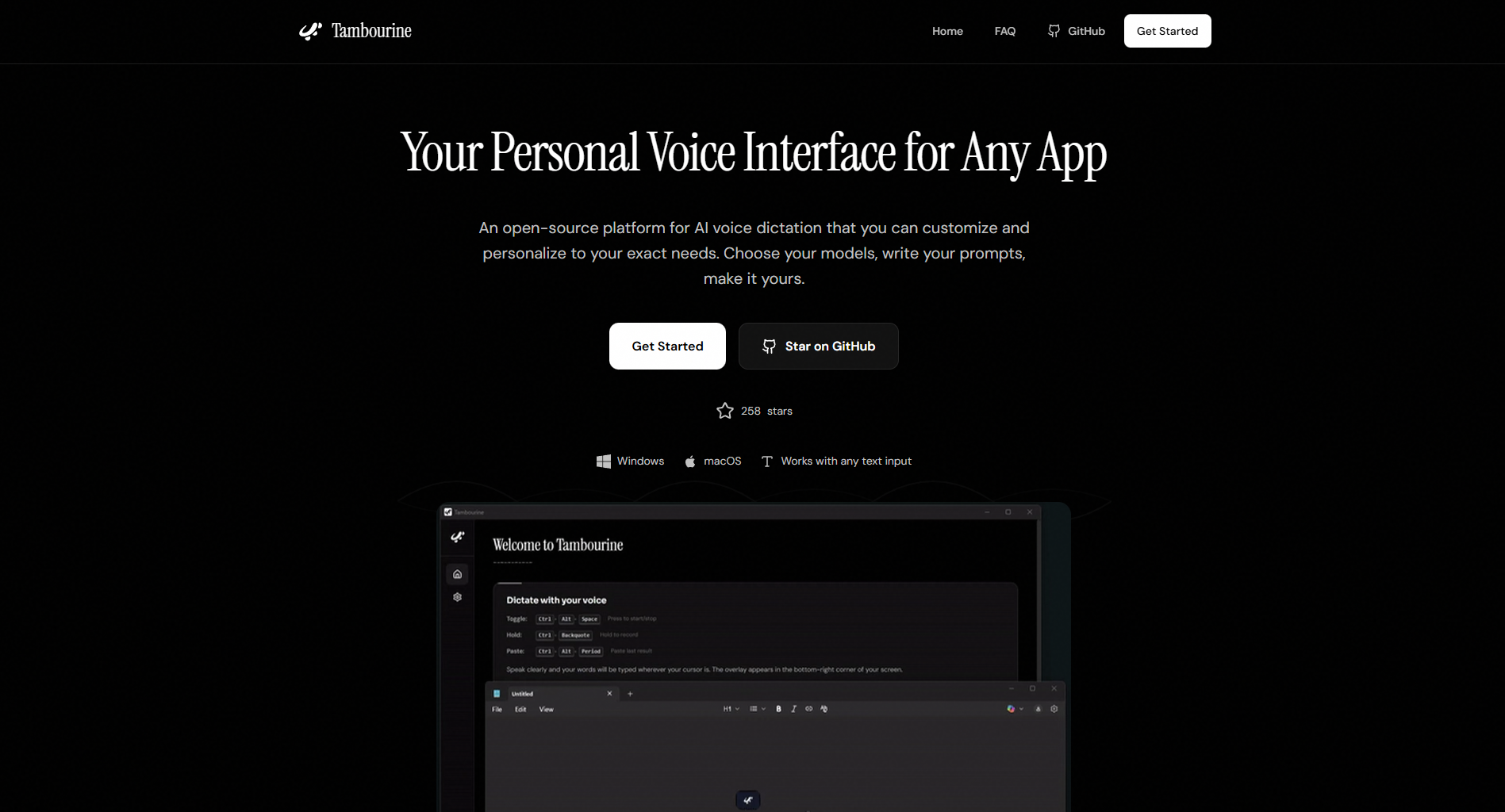
Tambourine Voiceは、あらゆるアプリケーションで利用可能なAI駆動型音声入力インターフェースを実現するオープンソースの個人用音声インタフェースです。ユーザーは、基盤となるモデル選択、プロンプト設計、動作ロジックを完全にカスタマイズ可能であり、技術的ワークフロー、アクセシビリティ要件、あるいは特定ドメイン向けの専門用語対応など、個別のニーズに応じて調整できます。主な利用者には、開発者、高度なユーザー、アクセシビリティ支援関係者、およびプロプライエタリな音声インタフェースに代わる透明性・自己ホスティング可能な代替手段を求める専門家が含まれます。
商用クローズドソース製品とは異なり、Tambourine Voiceはモジュール性と透明性を最優先しています。音声認識、テキスト整形、訂正処理などのコア機能はすべて、編集可能なプロンプトと設定可能なモデル連携によって実装されています。プラットフォームは、WhisperやOllamaを用いた完全ローカル推論から、サードパーティのクラウドAPIまで、多様なSTTおよびLLMバックエンドをサポートし、外部APIへの依存なしでの展開を可能にします。
Tambourine Voiceは、マイク入力をキャプチャし、ユーザーが選択したSTTモデルで音声をテキスト化した後、一連のカスタマイズ可能なLLMプロンプトによりそのテキストを処理する、システムレベルの音声インタフェースとして動作します。これらのプロンプトは、句読点挿入、大文字小文字変換、訂正処理、リスト構造化、およびドメイン固有の正規化(例:「ant row pic」→「Anthropic」)を制御します。ユーザーは「設定 → プロンプト」から直接これらのプロンプトを構成・編集します。
ワークフローは、ユーザーが手動またはホットキーで録音を開始し、自然な話し言葉で話すところから始まります。音声はテキストに変換され、現在のカーソル位置に挿入されます。「actually X」といった発話は、プロンプトベースのバックトラックロジックを起動して直前の出力を置き換えます。同様に、「one eggs two milk」といった表現は、ルールベースのプロンプトテンプレートを用いて番号付きリストに変換されます。すべてのモデル選択、プロンプト設計、および機能ロジックは、ローカル環境またはユーザーが管理するインフラストラクチャ上で実行されます。
Tambourine Voiceは、開発者(例:VS Codeなどのエディタへコードを音声入力)、ライター(長文原稿作成)、ビジネスパーソン(メール・ドキュメント作成)、およびアクセシビリティ支援を必要とする個人など、高効率なテキスト入力を求めるユーザーに適しています。拡張性により、技術文書作成(専門用語辞書活用)、会議メモ作成(自動リスト構造化)、およびコンテキスト依存編集(アクティブアプリケーションに応じたメール冒頭文やコードブロックの挿入)といったユースケースにも対応可能です。また、ローカル実行およびベンダー依存からの解放により、データプライバシー要件が厳格な環境やインターネット接続が制限された環境でも利用できます。