Enterprise-Grade Speech-to-Text API
Our ASR model can transcribe audio/video files in various formats into text, supporting two output formats: script and subtitles.
Demo Audio
Higher Accuracy
Exceptional performance in accuracy, with code-switching support for Chinese-English and Japanese-English.
Faster Processing
Ultra-fast: Convert a 1-hour audio/video file to text in 2 minutes.
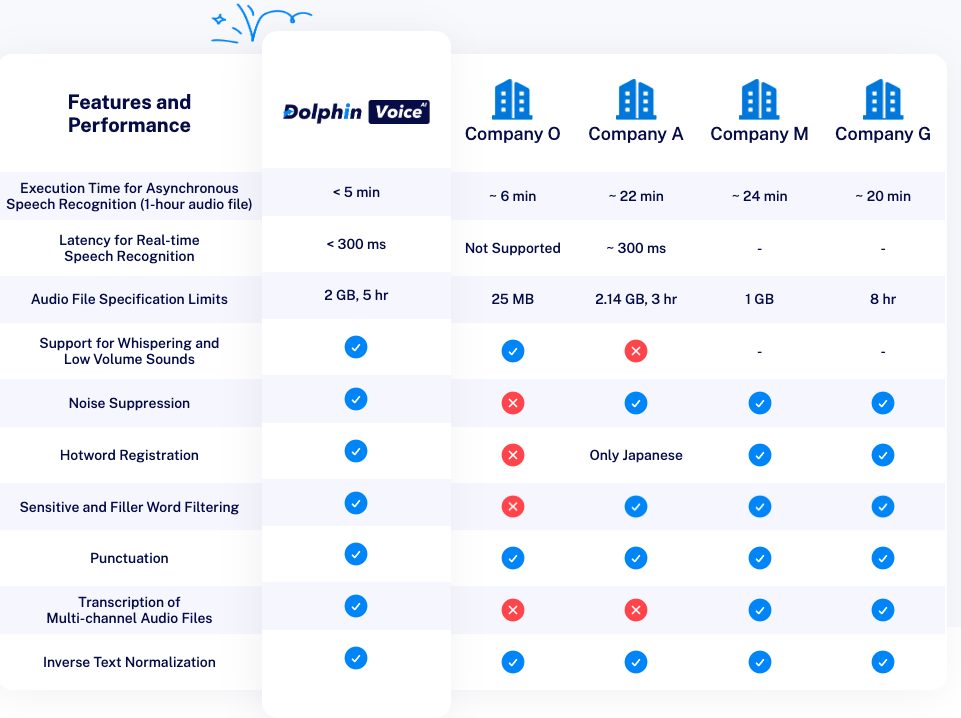
Features
View all featuresMulti-Domain Support
Support optimized models for call centers with enhanced accuracy.
Disfluency Detection
Polish text by filtering out filler words and improving flow for a smoother reading experience.
Smart Punctuation & Formatting
Automatic punctuation prediction and text format optimization to generate natural, readable transcripts.
Custom Vocabulary
Boost accuracy for proper nouns like names, places, and organizations with custom hot words.
Speaker Diarization
Distinguish between speakers through audio channels or voiceprint information.
Use Cases
Convert recorded meeting audio into accurate transcripts for archiving, sharing, and reviewing key points.
Transform interview recordings into searchable documents suitable for news interviews, academic research, and employee recruitment.
Transcribe recorded customer service calls for quality monitoring, training purposes, and compliance documentation.
Generate accurate subtitles and captions for podcasts and videos to enhance viewer experience and optimize searchability.
Generate precise transcripts from court reporting, hearings, and legal proceedings for case documentation.
Transcribe recorded lectures, seminars, and research interviews for analysis and knowledge preservation.
Create accurate transcripts for audio & video files for script editing, content repurposing, and post-production.
Automatically convert voicemails into text for quick review and efficient message management.




