PDF Extractor API(別名PDFex)は、PDF文書を構造化された機械読み取り可能なJSONデータに変換する、開発者向けのサービスです。請求書、領収書、フォーム、明細書などのビジネス文書から自動的にデータを抽出するアプリケーションを開発するソフトウェアエンジニアおよび開発チームを主な対象としています。手作業によるパースや信頼性の低いOCRベースのワークフローを排除することで、バックエンドシステムへのドキュメントデータの自動インジェストを実現します。
このサービスは予測可能性、パフォーマンス、および容易な統合を重視しています。一般的な文書タイプに対して一貫した出力スキーマを提供し、カスタムドキュメントレイアウト分析や個別のテンプレート保守を必要とせずに、迅速な開発サイクルと本番環境向けの自動化を支援します。
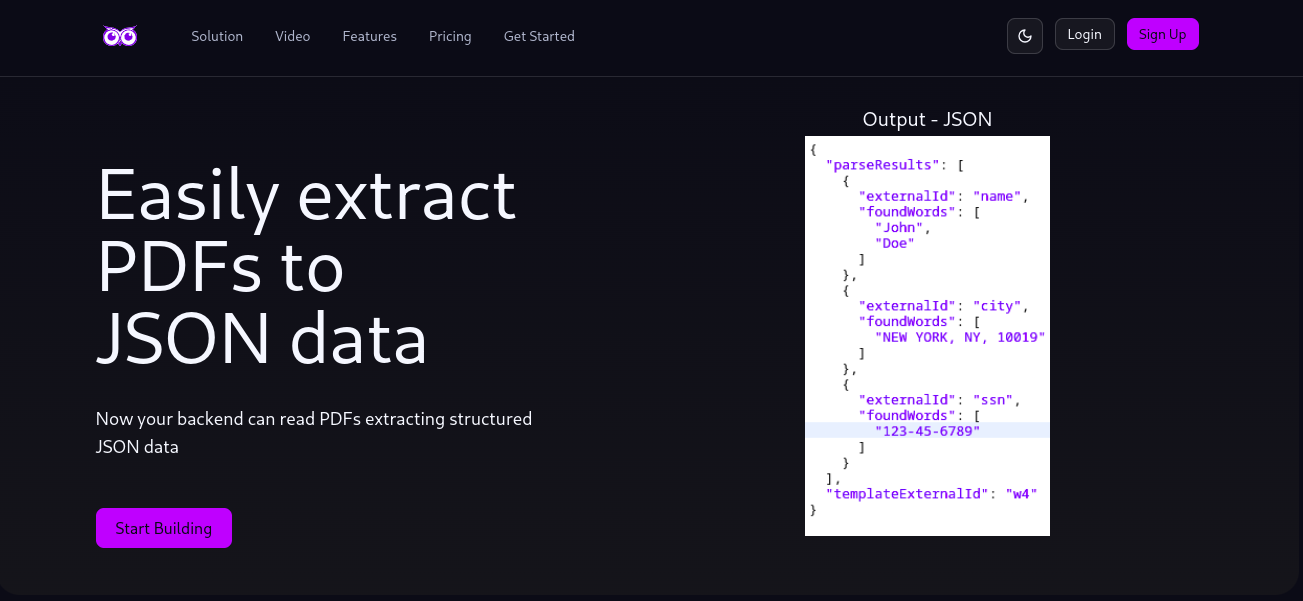
ユーザーはHTTP POSTリクエストをAPIエンドポイントに送信してPDFファイルを提出します。サービスは、レイアウト解析、セマンティックなフィールド検出、および一般的なビジネス文書向けに最適化された事前学習モデルを組み合わせて各ドキュメントを処理します。対応文書タイプでは、「請求金額」「顧客名」「ユーザー識別番号」などのキーフィールドを特定し、標準化されたJSONキーにマッピングします。
汎用文書(例:標準的な請求書フォーマット)については事前にテンプレート定義を必要としませんが、独自または非標準のドキュメント設計にはテンプレートベースの抽出が利用可能です。ユーザーはWebインターフェースを通じてPDFテンプレートを作成・フィールドマッピング・テストを行い、その後APIで使用できるようデプロイします。各テンプレートは期待されるフィールドとその位置またはパターンを定義し、精度向上を実現します。
出力は抽出値、メタデータ(例:信頼度スコア、ページ数)、および構造情報からなるJSONオブジェクトです。同一入力に対するレスポンスは決定論的であり、監査可能な処理や規制対応環境での利用を可能にします。
PDF Extractor APIは、非構造化または半構造化PDFから信頼性の高い構造化データを導出する必要があるユースケースを支援します。代表的な応用例には、自動化された支払処理(Accounts Payable)、顧客登録時の書類処理、財務諸表分析、および法的・規制要件への準拠報告があります。開発チームはETLパイプライン、文書管理システム、またはローコードプラットフォームへAPIを統合し、手作業によるデータ入力を代替し、人的ミスを低減します。
このサービスにより、カスタムパースロジックの開発・保守コストが削減され、ドキュメント自動化プロジェクトの実装期間が短縮されます。予測可能な出力フォーマットにより、フロントエンドおよびバックエンドチームが安定したインターフェース契約に基づいて開発を進められます。階層的な価格モデルは、初期評価から大規模な本番運用まで、明確な制約(ページ数、月間API呼び出し回数、テンプレート数)のもとで対応可能です。
| プラン | 月間リクエスト数 | PDF最大ページ数 | テンプレート数 | 料金 |
|---|---|---|---|---|
| 無料(ベータ) | 100 | 1 | 3 | $0 |
| Pro | 20,000 | 10 | 20 | $19/月 |
| Unlimited | 無制限 | 無制限 | 無制限 | $29/月 |