TextaVoiceの紹介
TextaVoiceは、アカウント不要で即時に利用可能なブラウザベースのAIテキスト読み上げ(TTS)ツールです。登録・サブスクリプション・ソフトウェアインストールを必要とせず、ユーザーが入力したテキストを自然な音声に変換します。主な対象ユーザーには、コンテンツ制作者、教育関係者、マーケター、ポッドキャスター、および多様な用途に対応した効率的かつスケーラブルな音声制作を求めるプロフェッショナルが含まれます。
本サービスは、ゼロフリクションなアクセスを重視しており、すべての機能がウェブブラウザ上で動作します。ユーザーの個人情報やアカウントとの紐付けは一切行わず、生成された音声はMP3形式でダウンロード可能であり、個人利用および商用利用の両方に対応しています。
主なポイント
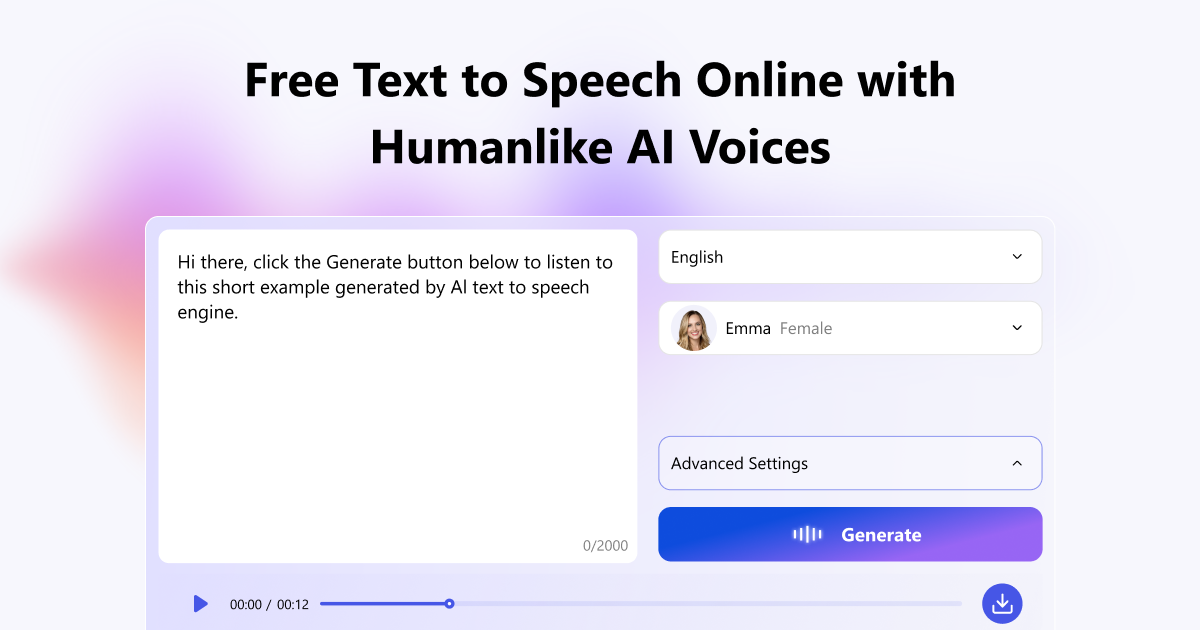
- アカウント不要:サインアップやログインなしで完全に利用可能
- 無制限の音声生成およびダウンロード:使用回数やクレジット制限なし
- 30以上の言語、83種類の音声、236種類の話し方スタイル(例:ニュートラル、明るい、悲しい、ささやき、物語風)をサポート
- 再生速度(0.5倍~2倍)、ピッチ、感情パラメータを調整可能で、細かい音声制御が可能
- 生成されたすべてのMP3音声は商用利用が許諾されており、ロイヤリティや出典表記は不要
- エンタープライズレベルのプライバシー保護:入力テキストは保存されず、ユーザー識別情報とは関連付けられない
- 1回の変換につき最大2,000文字まで対応し、段落・台本・ナレーションなどに最適化
- ファイルアップロード機能は未実装(テキストは貼り付けまたは直接入力のみ)
TextaVoiceの仕組み
TextaVoiceは3ステップのワークフローで動作します。(1)ユーザーがエディタにテキストを貼り付けまたは入力する。(2)言語・音声を選択し、再生速度、ピッチ、感情スタイルなどのオプション設定を調整する。(3)「生成」ボタンをクリックすると、AIがリアルタイムで音声を合成し、即座に再生およびMP3ダウンロードが可能になります。
基盤となる技術は高度なニューラルTTSモデルで、言語ごとの自然なイントネーション、リズム、発音を実現します。言語検出は自動で行われ、米国英語/英国英語、スペイン語(スペイン/メキシコ)、中国語(簡体字/繁体字)など、地域固有のバリエーションも含む多言語対応が特徴です。
主な利点と用途
TextaVoiceは複数の実用分野で活用されています。ポッドキャスターは、エピソードのプロトタイピングや多言語のイントロ/アウトロ作成に活用します。動画制作者はYouTube、TikTok、マーケティング向けのナレーションを生成し、人材依存を減らしながらブランドトーンの統一を図ります。教育関係者および出版社は、教科書、学習ノート、研修資料をカスタマイズ可能なAI音声でオーディオブック化します。プロフェッショナルはメール、報告書、メモを音声に変換し、通勤時などのマルチタスクを支援します。言語学習者は、30以上の言語でネイティブに近い発音の音声を活用して、聴解力と記憶定着を高めます。さらに、eラーニング開発者は、多言語対応と商用利用許諾を活かして、企業内研修やデジタル教育コンテンツにAIナレーションを統合できます。



